

Are you familiar with eBPF ? Do you know its purpose or how it works ?
Today, I’m trying to outline a brief overview of what, for me, is a revolutionary and very promising technology for the future of computing.
eBPF is a revolutionary technology with origins in the Linux kernel that can run sandboxed programs in a privileged context such as the operating system kernel. It is used to safely and efficiently extend the capabilities of the kernel without requiring to change kernel source code or load kernel modules.
(from the official eBPF website)
Note: This article is also available in french 🇫🇷.
At the time of writing (January 2024), eBPF can be used on all Linux systems (version >= 4.16) and is currently being developed for the Windows kernel.
eBPF enables kernel behavior to be reprogrammed without compromising security.
Katran is a load balancer that uses eBPF technology to filter packets directly in the kernel, avoiding over-processing and boosting performance.
Tetragon is a tool for monitoring and securing a kubernetes cluster, and also uses eBPF to track pods activity and raise alerts if the kernel executes suspicious tasks.
This article is the first of a series of articles dedicated to eBPF on the ACCEIS blog.
Aim
The purpose of this article is to explore the major concepts of this technology, providing you with insights into its ins and outs, and perhaps sparking your interest to learn more…?
Definition
eBPF is a technology for "hooking" on kernel behavior. This can be a system call (syscall) or a network event such as the arrival of a packet, or directly a specific kernel function. These hooks can be used to intervene before or after the execution of a kernel action.
The process of compiling and executing an eBPF program is a multi-stage one, and would merit a full article of its own, but we’ll confine ourselves to general definitions.
It’s important to note, however, that eBPF program execution takes place in a restricted environment for kernel security, but can transmit data into user space using eBPF maps.
The diagram below represents all the key eBPF concepts discussed in this article. It shows an eBPF program (represented by the bee) compiled and loaded into kernel space, and how it retrieves data and sends it to user space.
The difference between user space and kernel space lies in their usefulness. The aim of the kernel is to provide an abstraction layer over the entire hardware of a machine, thanks to an API (syscall). User space, on the other hand, uses these syscalls to interact with the end-user via an interface, which is the role of any Linux distribution, for example.
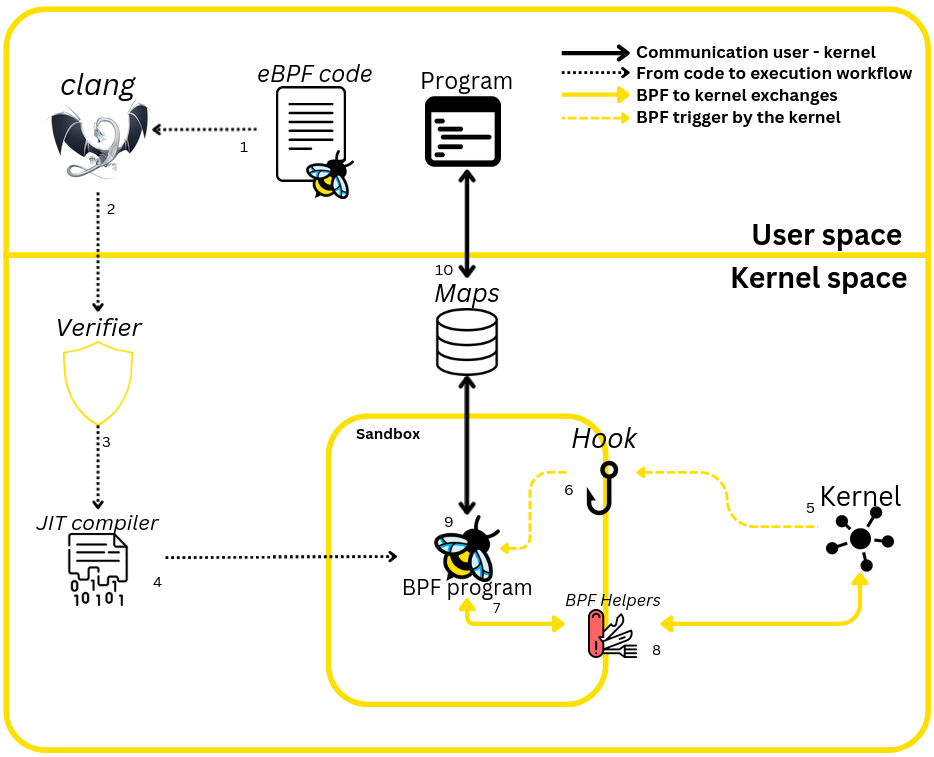
The diagram above shows how an eBPF program works : program initialization (1 to 4 in the figure), startup (5 and 6) and discussions with the kernel (7 and 8), through to communication between kernel space and user space (9 and 10).
Here’s an example of an eBPF hook program on the sys_enter_execve syscall. You’ll notice that an eBPF program is just a single function.
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
SEC("tp/syscalls/sys_enter_execve")
int acceis_hello_world(void *ctx) {
bpf_printk("Hello from Acceis !");
return 0;
}
char LICENSE[] SEC("license") = "Dual BSD/GPL";Program initialization (from 1 to 4)
To start an eBPF program, you need to go through 2 important steps. Unlike a standard program, the program cannot be executed directly by compilation alone. It must first be loaded into the kernel, which will take care of executing it when the time comes.
To compile the code, you need to use clang to transform it into eBPF bytecode.
clangis a compiler for LLVM
Once the bytecode has been obtained, it’s ready to be sent to the Verifier, which ensures that the program won’t compromise the kernel’s normal behavior by following a few rules.
Here are just a few:
- Loops must be of fixed size
- Stack frame limited to 512 bytes.
- 1 million instructions maximum (the verifier loops in the program to analyze the logic and must not exceed 1 million analyzed instructions).
After verifying its validity with the verifier, the program is loaded into the kernel and is compiled using the Just In Time Compiler (JIT), which translates the bytecode into machine code after performing various optimizations.
The program is then loaded into a sandbox, waiting to be hooked and executed.
Triggering the program (5 and 6)
When the hook is triggered, the kernel passes our function a context (ctx in the code above) which contains a certain amount of information. Depending on the hook chosen, its context differs, but in the case of syscalls or kernel probes, it contains the function parameters. For example, if the execve syscall is used, the context will contain data such as the name of the file (e.g. /usr/bin/ls) to be executed and the list of arguments passed to the command.
These can then be modified on the fly by our program, and returned to the kernel for execution.
execveis the syscall responsible for command execution on linux systems.
How the program works (7 and 8)
Being sandboxed, the eBPF program cannot execute network or system calls, but only dialogs with the kernel via an API built into the kernel, which provides functions called helpers. These functions retrieve data from the kernel and pass it on to our program.
You’ll find here a list of helpers that can be used.
In the context of our program presented above, the bpf_printk function is a macro offered by the bpf/bpf_helpers.h> API and is the equivalent of a printf in C.
User space – kernel space communication (9 and 10)
To transmit data to a so-called "standard" program (one that is not executed in the kernel context), the kernel has maps whose role is to store the data. These allow us to add, read and delete data from memory.
bpf_map_lookup_elem(),bpf_map_update_elem(),bpf_map_delete_elem(), are the 3 helpers responsible for manipulating maps.
A program in user space can then use these maps via libbpf in the same way as an eBPF program.
What next … ?
Next week, you’ll be able to read a new article on the eBPF, focusing on a specific aspect of the linux kernel.
Here’s a sneak preview of the title: eBPF program creation in practice - PID concealment (Part 1)
Glossary
Verifier
Tool implemented directly in the kernel to ensure that a program is "healthy" for the kernel, i.e. that it will not hinder its operation. Several rules must be respected, such as a stack frame of 512 bytes and restrictions on loops.
Hooks
An anchor point for a kernel function. This can be a syscall, a behavior on cgroups, a network event or a specific kernel function.
Example of a possible attachment point :
- Kprobe / Kretprobe / Uprobe / Uretprobe
- Tracepoint
- Traffic control (TC)
- Cgroup
- XDP
The complete list on the BCC repository
Helpers
Functions for interacting with the kernel and maps.
Maps
Data structure for storing and retrieving data. A large number of data structures are possible, listed in the official documentation.
Further information
- The history of eBPF
- Excellent book for learning
- 2 fun learning labs
- eBPF tutorials
- A great blog for further reading
- List of major projects using eBPF
About the author
Article written by Tristan d’Audibert aka Sathi, cybersecurity engineer apprentice at ACCEIS.